Postage Stamps
Postage stamps are used to pay for storing data on Swarm. They are purchased in batches, granting a prepaid right to store data on Swarm, similar to how real-world postage stamps pay for mail delivery.
When a node uploads data to Swarm, it 'attaches' postage stamps to each chunk of data. The value assigned to a stamp indicates how much it is worth to persist the associated data on Swarm, which nodes use to prioritize which chunks to remove from their reserve first.
The value of a postage stamp decreases over time as if storage rent was regularly deducted from the batch balance. A stamp expires when its batch runs out of balance. Chunks with expired stamps cannot be used as proof in the redistribution game, meaning storer nodes will no longer receive rewards for storing them and can safely remove them from their reserves.
Postage stamp prices are dynamically set based on a utilization signal supplied by the price oracle smart contract. Prices will automatically increase or decrease according to the level of utilization.
Batch Buckets
Postage stamps are issued in batches with a certain number of storage slots partitioned into equally sized address space buckets (bucket depth has a fixed value of 16). Each bucket is responsible for storing chunks that fall within a certain range of the address space. When uploaded, files are split into 4kb chunks, each chunk is assigned a unique address, and each chunk is then assigned to the bucket in which its address falls.
Bucket Size
Bucket depth determines how the address space is partitioned, with each bucket storing chunks that share a common address prefix. Each bucket contains a fixed number of slots, each capable of storing a stamped chunk. Once all slots in any single bucket are filled, the entire postage batch becomes fully utilized, preventing further uploads.
Together with batch depth, bucket depth determines how many chunks are allowed in each bucket. The number of chunks allowed in each bucket is calculated like so:
So with a batch depth of 24 and a bucket depth of 16:
Note that due how buckets fill as described above, a batch can become fully utilised before its theoretical maximum volume has been reached. See batch utilisation section below for more information.
Batch Depth and Batch Amount
Each batch of stamps has two key parameters, batch depth and amount, which are recorded on Gnosis Chain at issuance. Note that these "depths" do not refer to the depth terms used to describe topology which are outlined here in the glossary.
Batch Depth
The minimum value for depth is 17, however higher depths are recommended for most use cases due to the mechanics of stamp batch utilisation. See the depths utilisation table to help decide which depth is best for your use case.
Batch depth determines how much data can be stored by a batch. The number of chunks which can be stored (stamped) by a batch is equal to .
For a batch with a batch depth of 24, a maximum of chunks can be stamped.
Since we know that one chunk can store 4 kb of data, we can calculate the theoretical maximum amount of data which can be stored by a batch from the batch depth.
However, due to the way postage stamp batches are utilised, batches will become fully utilised before stamping the theoretical maximum number of chunks. Therefore when deciding which batch depth to use, it is important to consider the effective amount of data that can be stored by a batch, and not the theoretical maximum. The effective rate of utilisation increases along with the batch depth. See section on stamp batch utilisation below for more information.
Batch Amount (& Batch Cost)
The amount parameter is the quantity of xBZZ in PLUR that is assigned per chunk in the batch. The total number of xBZZ that will be paid for the batch is calculated from this figure and the batch depth like so:
The paid xBZZ forms the balance of the batch. This balance is then slowly depleted as time ticks on and blocks are mined on Gnosis Chain.
For example, with a batch depth of 24 and an amount of 1000000000 PLUR:
Calculating amount needed for desired TTL
To calculate the required amount, divide the current postage price by the Gnosis block time (5 sec) and multiply by the desired storage duration in seconds. For the example below we assume a stamp price of 24000 PLUR / chunk / block:
The postage stamp price is dynamically determined according to a network utilisation signal. You can view the current storage price at Swarmscan.io.
There are 1036800 seconds in 12 days, so the amount value required to store for 12 days can be calculated:
So we can use 4976640000 as our amount value in order for our postage batch to store data for 12 days.
Batch Utilisation
There are two types of postage stamp batches: immutable and mutable. Immutable batches permanently store data, while mutable batches allow overwriting older data as new chunks are added.
Immutable Batches
Utilisation of an immutable batch is computed using a hash map of size which is for all batches, so 65536 total entries. For the keys of the key-value pairs of the hash map, the keys are 16 digit binary numbers from 0 to 65535, and the value is a counter.
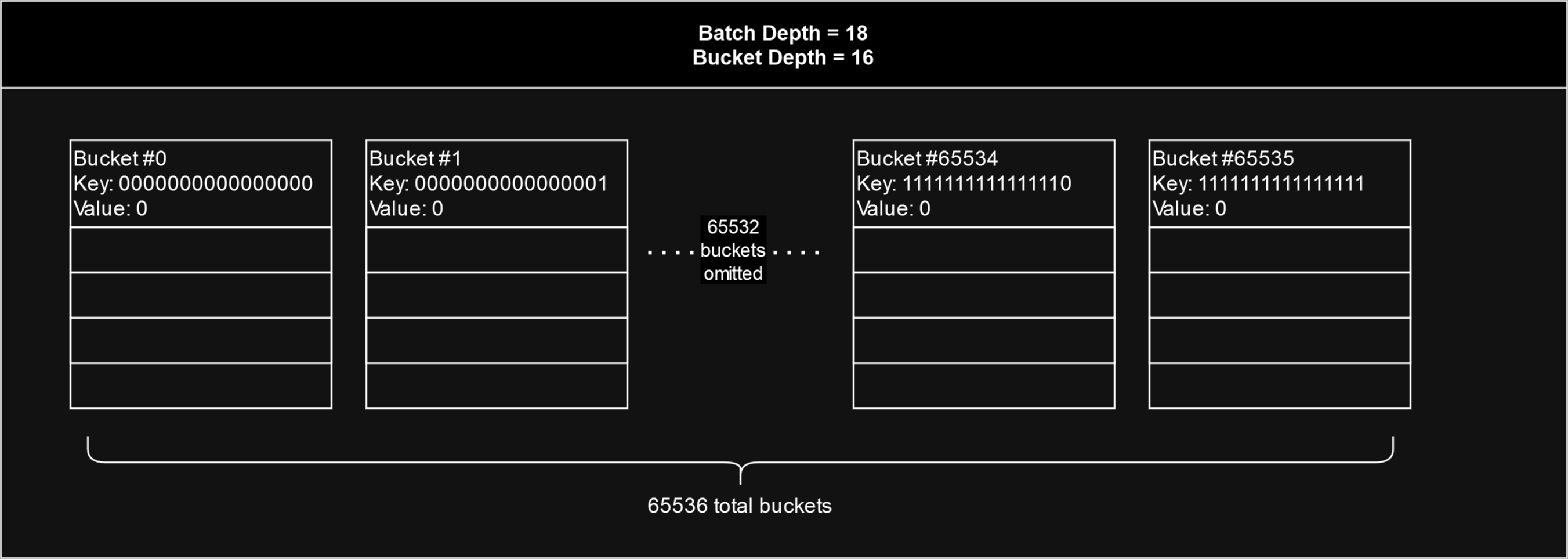
As chunks are uploaded to Swarm, each chunk is assigned to a bucket based the first 16 binary digits of the chunk's hash. The chunk will be assigned to whichever bucket's key matches the first 16 bits of its hash, and that bucket's counter will be incremented by 1.
The batch is deemed "full" when ANY of these counters reach a certain max value. The max value is computed from the batch depth as such: . For example with batch depth of 24, the max value is or 256. A bucket can be thought of as have a number of "slots" equal to this maximum value, and every time the bucket's counter is incremented, one of its slots gets filled.
In the diagram below, the batch depth is 18, so there are or 4 slots for each bucket. The utilisation of a batch is simply the highest number of filled slots out of all 65536 entries or "buckets". In this batch, none of the slots in any of the buckets have yet been filled with 4 chunks, so the batch is not yet fully utilised. The most filled slots out of all buckets is 2, so the stamp batch's utilisation is 2 out of 4.
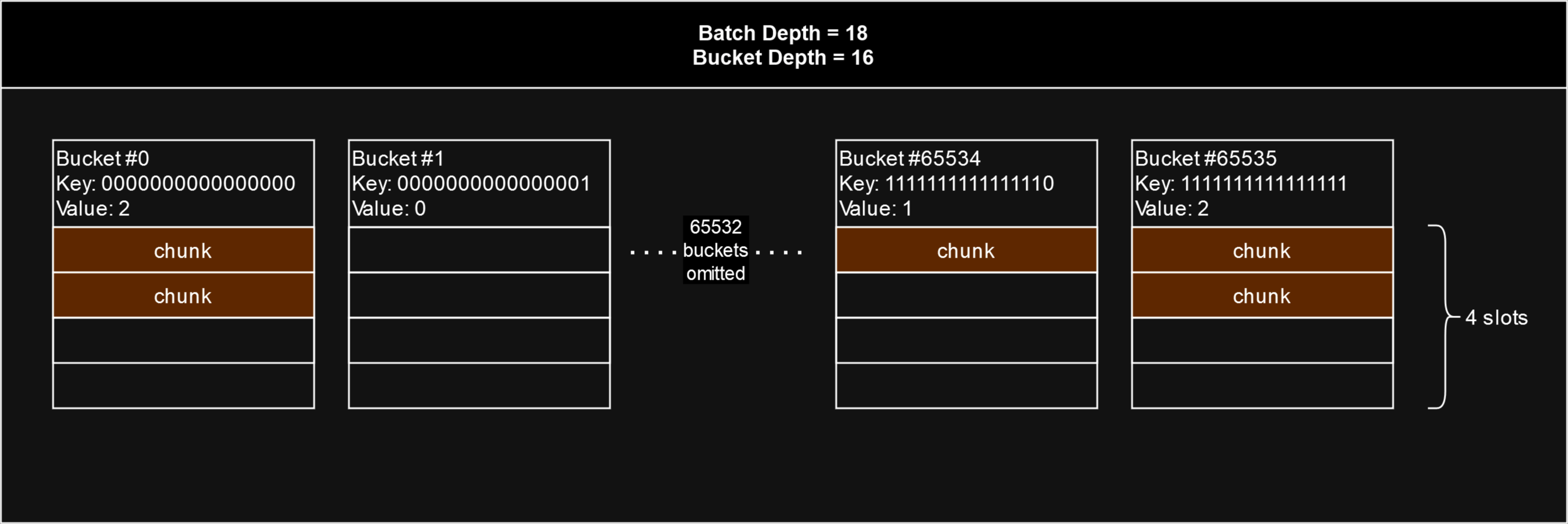
As more chunks get uploaded and stamped, the bucket slots will begin to fill. As soon as the slots for any SINGLE bucket get filled, the entire batch is considered 100% utilised and can no longer be used to upload additional chunks.
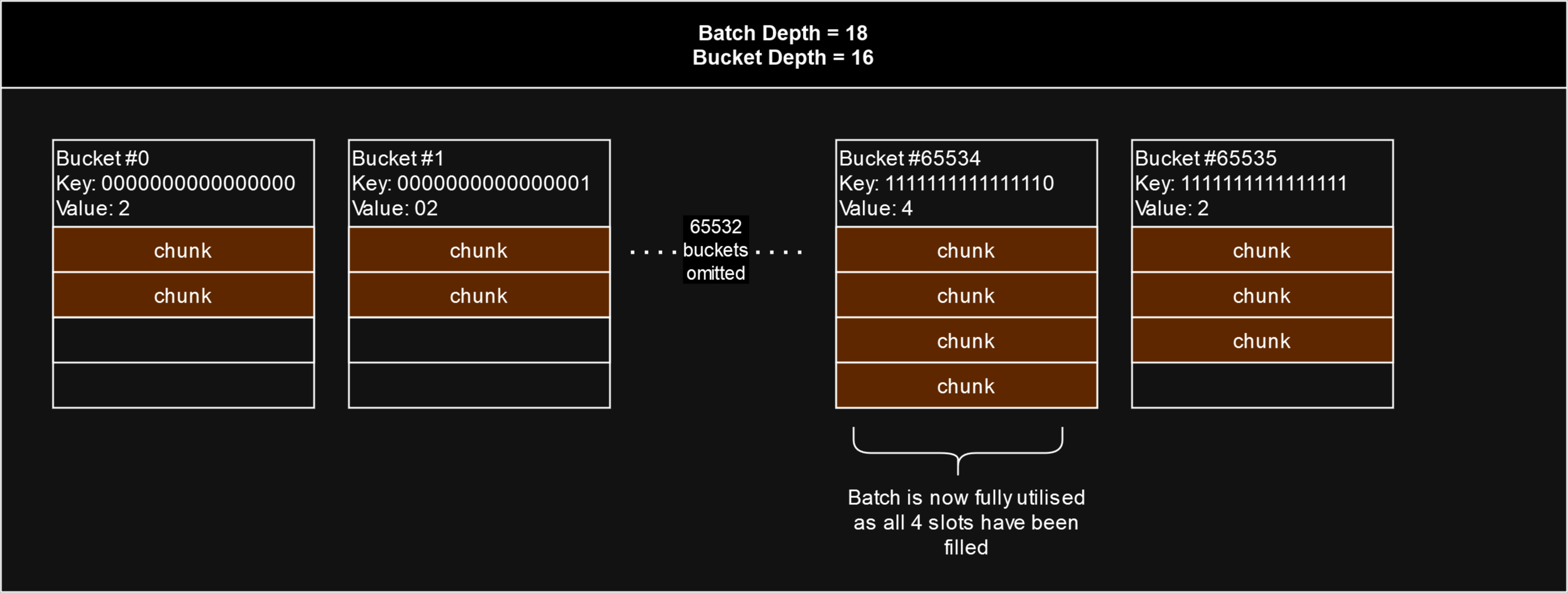
Mutable Batches
Mutable batches use the same hash map structure as immutable batches, however its utilisation works very differently. In contrast with immutable batches, mutable batches are never considered fully utilised. Rather, at the point where an immutable batch would be considered fully utilised, a mutable batch can continue to stamp chunks. However, if any chunk's address lands in a bucket whose slots are already filled, rather than the batch becoming fully utilised, that bucket's counter gets reset, and the new chunk will replace the oldest chunk in that bucket.
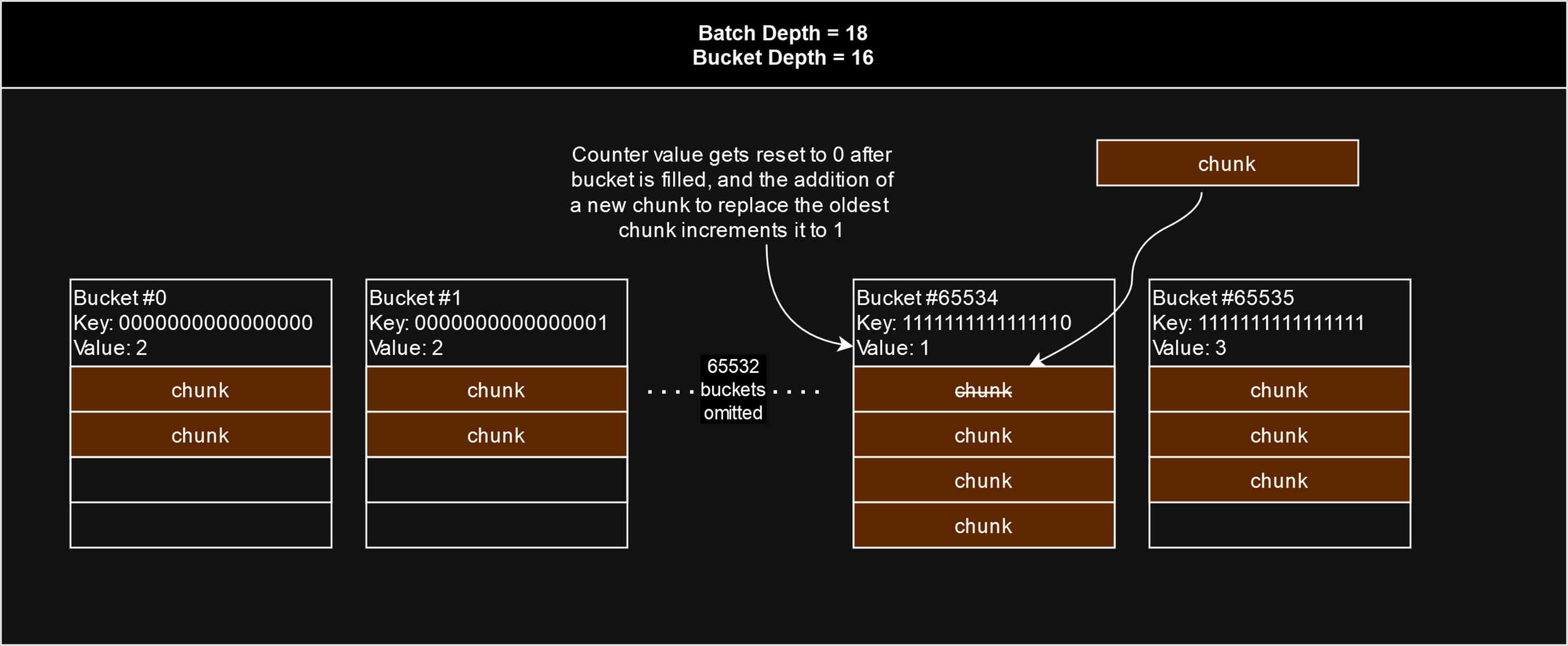
Therefore rather than speaking of the number of slots as determining the utilisation of a batch as with immutable batches, we can think of the slots as defining a limit to the amount of data which can be uploaded before old data starts to get overwritten.
Which Type of Batch to Use
Immutable batches are suitable for long term storage of data or for data which otherwise does not need to be changed and should never be overwritten, such as records archival, legal documents, family photos, etc.
Mutable batches are great for data which needs to be frequently updated and does not require a guarantee of immutability. For example, a blog, personal or company websites, ephemeral messaging app, etc.
The default batch type when unspecified is immutable. This can be modified through the Bee api by setting the immutable header with the \stamps POST endpoint to false.
Re-uploading
There are several nuances to how the re-uploading of previously uploaded data to Swarm affect stamp batch utilisation. For single chunks, the behaviour is relatively straightforward, however with files that must get split into multiple chunks, the behaviour is less straightforward.
Single chunks
When a chunk which has previously been uploaded to Swarm is re-uploaded from the same node while the initial postage batch it was stamped by is still valid, no additional stamp will be utilised from the batch. However if the chunk comes from a different node than the original node, then a stamp WILL be utilised, and as long as at least one of the batches the chunk was stamped by is still valid, the chunk will be retained by storer nodes in its neighborhood.
Files
When an identical file is re-uploaded then the stamp utilisation behaviour will be the same as with single chunks described in the section above. However, if part of the file has been modified and then re-uploaded, stamp utilisation behaviour will be different. This is due to how the chunking process works when a file is uploaded to Swarm. When uploaded to Swarm, files are split into 4kb sized chunks (2^12 bytes), and each chunk is assigned an address which is based on the content of the chunk. If even a single bit within the chunk is modified, then the address of the chunk will also be modified.
When a file which was previously uploaded with a single bit flipped is again split into chunks by a node before being uploaded to Swarm, then only the chunk with the flipped bit will have an updated address and require the utilisation of another stamp. The content of all the other chunks will remain the same, and therefore will not require new stamps to be utilised.
However, if rather than flipping a single bit we add some data to our file, this could cause changes in the content of every chunk of the file, meaning that every single chunk must be re-stamped. We can use a simplified example of why this is the case to more easily understand the stamp utilisation behaviour. Let us substitute a message containing letters of the alphabet rather than binary data.
Our initial message consists of 16 letters:
abcdefghijklmnop
When initially uploaded, it will be split into four chunks of four letters each:
abcdefghijklmnop => abcd | efgh | ijkl | mnop
Let us look at what happens when a single letter is changed (here we change a to z):
abcdefghijklmnop => zbcd | efgh | ijkl | mnop
In this case, only the first chunk is affected, all the other chunks retain the same content.
Now let is examine the case where a new letter is added rather than simply modifying an already existing one. Here we add the number 1 at the start of the message:
1abcdefghijklmnop => 1abc | defg | hijk | lmno | p
As you can see, by adding a single new letter at the start of the message, all the letters are shifted to the right by a single position, which a has caused EVERY chunk in the message to be modified rather than just a single chunk.
Affect on Batch Utilisation
The implications of this behaviour are that even a small change to the data of a file may cause every single chunk from the file to be changed, meaning that new stamps must be utilised for every chunk from that file. In practice, this could lead to high costs in data which is frequently changed, since for even a small change, every chunk from the file must be re-stamped.
Implications for Swarm Users
Due to the nature of batch utilisation described above, batches are often fully utilised before reaching their theoretical maximum storage amount. However as the batch depth increases, the chance of a postage batch becoming fully utilised early decreases. At batch depth 24 (unencrypted, no erasure coding), there is a 0.1% chance that a batch will be fully utilised/start replacing old chunks before reaching 68.48% of its theoretical maximum.
Let's look at an example to make it clearer. Using the method of calculating the theoretical maximum storage amount outlined above, we can see that for a batch depth of 24, the theoretical maximum amount which can be stored is 68.72 gb:
Therefore we should use 68.48% the effective rate of usage for the stamp batch:
Note that the effective volume also depends on the encryption and erasure coding settings used. The example above assumes unencrypted data with no erasure coding. See the effective utilisation tables below for the full set of effective volumes.
Effective Utilisation Tables
When a user buys a batch of stamps they may make the naive assumption that they will be able to upload data equal to the sum total size of the maximum capacity of the batch. However, in practice this assumption is incorrect, so it is essential that Swarm users understand the relationship between batch depth and the theoretical and effective volumes of a batch.
Columns:
- Theoretical Volume: The theoretical maximum volume which can be reached if the batch is completely utilized.
- Effective Volume: The actual volume which a batch can be expected to store with a failure rate of less than or equal to 0.1% (1 in 1000).
- Batch Depth: The batch depth value.
The title of each table below states whether it is for encrypted or unencrypted uploads along with the erasure coding level.
Erasure coding on Swarm has five named levels:
- NONE
- MEDIUM
- STRONG
- INSANE
- PARANOID
Unencrypted - NONE
| Theoretical Volume | Effective Volume | Batch Depth |
|---|---|---|
| 536.87 MB | 44.70 kB | 17 |
| 1.07 GB | 6.66 MB | 18 |
| 2.15 GB | 112.06 MB | 19 |
| 4.29 GB | 687.62 MB | 20 |
| 8.59 GB | 2.60 GB | 21 |
| 17.18 GB | 7.73 GB | 22 |
| 34.36 GB | 19.94 GB | 23 |
| 68.72 GB | 47.06 GB | 24 |
| 137.44 GB | 105.51 GB | 25 |
| 274.88 GB | 227.98 GB | 26 |
| 549.76 GB | 476.68 GB | 27 |
| 1.10 TB | 993.65 GB | 28 |
| 2.20 TB | 2.04 TB | 29 |
| 4.40 TB | 4.17 TB | 30 |
| 8.80 TB | 8.45 TB | 31 |
| 17.59 TB | 17.07 TB | 32 |
| 35.18 TB | 34.36 TB | 33 |
| 70.37 TB | 69.04 TB | 34 |
| 140.74 TB | 138.54 TB | 35 |
| 281.47 TB | 277.72 TB | 36 |
| 562.95 TB | 556.35 TB | 37 |
| 1.13 PB | 1.11 PB | 38 |
| 2.25 PB | 2.23 PB | 39 |
| 4.50 PB | 4.46 PB | 40 |
| 9.01 PB | 8.93 PB | 41 |
Unencrypted - MEDIUM
| Theoretical Volume | Effective Volume | Batch Depth |
|---|---|---|
| 536.87 MB | 41.56 kB | 17 |
| 1.07 GB | 6.19 MB | 18 |
| 2.15 GB | 104.18 MB | 19 |
| 4.29 GB | 639.27 MB | 20 |
| 8.59 GB | 2.41 GB | 21 |
| 17.18 GB | 7.18 GB | 22 |
| 34.36 GB | 18.54 GB | 23 |
| 68.72 GB | 43.75 GB | 24 |
| 137.44 GB | 98.09 GB | 25 |
| 274.88 GB | 211.95 GB | 26 |
| 549.76 GB | 443.16 GB | 27 |
| 1.10 TB | 923.78 GB | 28 |
| 2.20 TB | 1.90 TB | 29 |
| 4.40 TB | 3.88 TB | 30 |
| 8.80 TB | 7.86 TB | 31 |
| 17.59 TB | 15.87 TB | 32 |
| 35.18 TB | 31.94 TB | 33 |
| 70.37 TB | 64.19 TB | 34 |
| 140.74 TB | 128.80 TB | 35 |
| 281.47 TB | 258.19 TB | 36 |
| 562.95 TB | 517.23 TB | 37 |
| 1.13 PB | 1.04 PB | 38 |
| 2.25 PB | 2.07 PB | 39 |
| 4.50 PB | 4.15 PB | 40 |
| 9.01 PB | 8.30 PB | 41 |
Unencrypted - STRONG
| Theoretical Volume | Effective Volume | Batch Depth |
|---|---|---|
| 536.87 MB | 37.37 kB | 17 |
| 1.07 GB | 5.57 MB | 18 |
| 2.15 GB | 93.68 MB | 19 |
| 4.29 GB | 574.81 MB | 20 |
| 8.59 GB | 2.17 GB | 21 |
| 17.18 GB | 6.46 GB | 22 |
| 34.36 GB | 16.67 GB | 23 |
| 68.72 GB | 39.34 GB | 24 |
| 137.44 GB | 88.20 GB | 25 |
| 274.88 GB | 190.58 GB | 26 |
| 549.76 GB | 398.47 GB | 27 |
| 1.10 TB | 830.63 GB | 28 |
| 2.20 TB | 1.71 TB | 29 |
| 4.40 TB | 3.49 TB | 30 |
| 8.80 TB | 7.07 TB | 31 |
| 17.59 TB | 14.27 TB | 32 |
| 35.18 TB | 28.72 TB | 33 |
| 70.37 TB | 57.71 TB | 34 |
| 140.74 TB | 115.81 TB | 35 |
| 281.47 TB | 232.16 TB | 36 |
| 562.95 TB | 465.07 TB | 37 |
| 1.13 PB | 931.23 TB | 38 |
| 2.25 PB | 1.86 PB | 39 |
| 4.50 PB | 3.73 PB | 40 |
| 9.01 PB | 7.46 PB | 41 |
Unencrypted - INSANE
| Theoretical Volume | Effective Volume | Batch Depth |
|---|---|---|
| 536.87 MB | 33.88 kB | 17 |
| 1.07 GB | 5.05 MB | 18 |
| 2.15 GB | 84.92 MB | 19 |
| 4.29 GB | 521.09 MB | 20 |
| 8.59 GB | 1.97 GB | 21 |
| 17.18 GB | 5.86 GB | 22 |
| 34.36 GB | 15.11 GB | 23 |
| 68.72 GB | 35.66 GB | 24 |
| 137.44 GB | 79.96 GB | 25 |
| 274.88 GB | 172.77 GB | 26 |
| 549.76 GB | 361.23 GB | 27 |
| 1.10 TB | 753.00 GB | 28 |
| 2.20 TB | 1.55 TB | 29 |
| 4.40 TB | 3.16 TB | 30 |
| 8.80 TB | 6.41 TB | 31 |
| 17.59 TB | 12.93 TB | 32 |
| 35.18 TB | 26.04 TB | 33 |
| 70.37 TB | 52.32 TB | 34 |
| 140.74 TB | 104.99 TB | 35 |
| 281.47 TB | 210.46 TB | 36 |
| 562.95 TB | 421.61 TB | 37 |
| 1.13 PB | 844.20 TB | 38 |
| 2.25 PB | 1.69 PB | 39 |
| 4.50 PB | 3.38 PB | 40 |
| 9.01 PB | 6.77 PB | 41 |
Unencrypted - PARANOID
| Theoretical Volume | Effective Volume | Batch Depth |
|---|---|---|
| 536.87 MB | 13.27 kB | 17 |
| 1.07 GB | 1.98 MB | 18 |
| 2.15 GB | 33.27 MB | 19 |
| 4.29 GB | 204.14 MB | 20 |
| 8.59 GB | 771.13 MB | 21 |
| 17.18 GB | 2.29 GB | 22 |
| 34.36 GB | 5.92 GB | 23 |
| 68.72 GB | 13.97 GB | 24 |
| 137.44 GB | 31.32 GB | 25 |
| 274.88 GB | 67.68 GB | 26 |
| 549.76 GB | 141.51 GB | 27 |
| 1.10 TB | 294.99 GB | 28 |
| 2.20 TB | 606.90 GB | 29 |
| 4.40 TB | 1.24 TB | 30 |
| 8.80 TB | 2.51 TB | 31 |
| 17.59 TB | 5.07 TB | 32 |
| 35.18 TB | 10.20 TB | 33 |
| 70.37 TB | 20.50 TB | 34 |
| 140.74 TB | 41.13 TB | 35 |
| 281.47 TB | 82.45 TB | 36 |
| 562.95 TB | 165.17 TB | 37 |
| 1.13 PB | 330.72 TB | 38 |
| 2.25 PB | 661.97 TB | 39 |
| 4.50 PB | 1.32 PB | 40 |
| 9.01 PB | 2.65 PB | 41 |
Encrypted - NONE
| Theoretical Volume | Effective Volume | Batch Depth |
|---|---|---|
| 536.87 MB | 44.35 kB | 17 |
| 1.07 GB | 6.61 MB | 18 |
| 2.15 GB | 111.18 MB | 19 |
| 4.29 GB | 682.21 MB | 20 |
| 8.59 GB | 2.58 GB | 21 |
| 17.18 GB | 7.67 GB | 22 |
| 34.36 GB | 19.78 GB | 23 |
| 68.72 GB | 46.69 GB | 24 |
| 137.44 GB | 104.68 GB | 25 |
| 274.88 GB | 226.19 GB | 26 |
| 549.76 GB | 472.93 GB | 27 |
| 1.10 TB | 985.83 GB | 28 |
| 2.20 TB | 2.03 TB | 29 |
| 4.40 TB | 4.14 TB | 30 |
| 8.80 TB | 8.39 TB | 31 |
| 17.59 TB | 16.93 TB | 32 |
| 35.18 TB | 34.09 TB | 33 |
| 70.37 TB | 68.50 TB | 34 |
| 140.74 TB | 137.45 TB | 35 |
| 281.47 TB | 275.53 TB | 36 |
| 562.95 TB | 551.97 TB | 37 |
| 1.13 PB | 1.11 PB | 38 |
| 2.25 PB | 2.21 PB | 39 |
| 4.50 PB | 4.43 PB | 40 |
| 9.01 PB | 8.86 PB | 41 |
Encrypted - MEDIUM
| Theoretical Volume | Effective Volume | Batch Depth |
|---|---|---|
| 536.87 MB | 40.89 kB | 17 |
| 1.07 GB | 6.09 MB | 18 |
| 2.15 GB | 102.49 MB | 19 |
| 4.29 GB | 628.91 MB | 20 |
| 8.59 GB | 2.38 GB | 21 |
| 17.18 GB | 7.07 GB | 22 |
| 34.36 GB | 18.24 GB | 23 |
| 68.72 GB | 43.04 GB | 24 |
| 137.44 GB | 96.50 GB | 25 |
| 274.88 GB | 208.52 GB | 26 |
| 549.76 GB | 435.98 GB | 27 |
| 1.10 TB | 908.81 GB | 28 |
| 2.20 TB | 1.87 TB | 29 |
| 4.40 TB | 3.81 TB | 30 |
| 8.80 TB | 7.73 TB | 31 |
| 17.59 TB | 15.61 TB | 32 |
| 35.18 TB | 31.43 TB | 33 |
| 70.37 TB | 63.15 TB | 34 |
| 140.74 TB | 126.71 TB | 35 |
| 281.47 TB | 254.01 TB | 36 |
| 562.95 TB | 508.85 TB | 37 |
| 1.13 PB | 1.02 PB | 38 |
| 2.25 PB | 2.04 PB | 39 |
| 4.50 PB | 4.08 PB | 40 |
| 9.01 PB | 8.17 PB | 41 |
Encrypted - STRONG
| Theoretical Volume | Effective Volume | Batch Depth |
|---|---|---|
| 536.87 MB | 36.73 kB | 17 |
| 1.07 GB | 5.47 MB | 18 |
| 2.15 GB | 92.07 MB | 19 |
| 4.29 GB | 564.95 MB | 20 |
| 8.59 GB | 2.13 GB | 21 |
| 17.18 GB | 6.35 GB | 22 |
| 34.36 GB | 16.38 GB | 23 |
| 68.72 GB | 38.66 GB | 24 |
| 137.44 GB | 86.69 GB | 25 |
| 274.88 GB | 187.31 GB | 26 |
| 549.76 GB | 391.64 GB | 27 |
| 1.10 TB | 816.39 GB | 28 |
| 2.20 TB | 1.68 TB | 29 |
| 4.40 TB | 3.43 TB | 30 |
| 8.80 TB | 6.94 TB | 31 |
| 17.59 TB | 14.02 TB | 32 |
| 35.18 TB | 28.23 TB | 33 |
| 70.37 TB | 56.72 TB | 34 |
| 140.74 TB | 113.82 TB | 35 |
| 281.47 TB | 228.18 TB | 36 |
| 562.95 TB | 457.10 TB | 37 |
| 1.13 PB | 915.26 TB | 38 |
| 2.25 PB | 1.83 PB | 39 |
| 4.50 PB | 3.67 PB | 40 |
| 9.01 PB | 7.34 PB | 41 |
Encrypted - INSANE
| Theoretical Volume | Effective Volume | Batch Depth |
|---|---|---|
| 536.87 MB | 33.26 kB | 17 |
| 1.07 GB | 4.96 MB | 18 |
| 2.15 GB | 83.38 MB | 19 |
| 4.29 GB | 511.65 MB | 20 |
| 8.59 GB | 1.93 GB | 21 |
| 17.18 GB | 5.75 GB | 22 |
| 34.36 GB | 14.84 GB | 23 |
| 68.72 GB | 35.02 GB | 24 |
| 137.44 GB | 78.51 GB | 25 |
| 274.88 GB | 169.64 GB | 26 |
| 549.76 GB | 354.69 GB | 27 |
| 1.10 TB | 739.37 GB | 28 |
| 2.20 TB | 1.52 TB | 29 |
| 4.40 TB | 3.10 TB | 30 |
| 8.80 TB | 6.29 TB | 31 |
| 17.59 TB | 12.70 TB | 32 |
| 35.18 TB | 25.57 TB | 33 |
| 70.37 TB | 51.37 TB | 34 |
| 140.74 TB | 103.08 TB | 35 |
| 281.47 TB | 206.65 TB | 36 |
| 562.95 TB | 413.98 TB | 37 |
| 1.13 PB | 828.91 TB | 38 |
| 2.25 PB | 1.66 PB | 39 |
| 4.50 PB | 3.32 PB | 40 |
| 9.01 PB | 6.64 PB | 41 |
Encrypted - PARANOID
| Theoretical Volume | Effective Volume | Batch Depth |
|---|---|---|
| 536.87 MB | 13.17 kB | 17 |
| 1.07 GB | 1.96 MB | 18 |
| 2.15 GB | 33.01 MB | 19 |
| 4.29 GB | 202.53 MB | 20 |
| 8.59 GB | 765.05 MB | 21 |
| 17.18 GB | 2.28 GB | 22 |
| 34.36 GB | 5.87 GB | 23 |
| 68.72 GB | 13.86 GB | 24 |
| 137.44 GB | 31.08 GB | 25 |
| 274.88 GB | 67.15 GB | 26 |
| 549.76 GB | 140.40 GB | 27 |
| 1.10 TB | 292.67 GB | 28 |
| 2.20 TB | 602.12 GB | 29 |
| 4.40 TB | 1.23 TB | 30 |
| 8.80 TB | 2.49 TB | 31 |
| 17.59 TB | 5.03 TB | 32 |
| 35.18 TB | 10.12 TB | 33 |
| 70.37 TB | 20.34 TB | 34 |
| 140.74 TB | 40.80 TB | 35 |
| 281.47 TB | 81.80 TB | 36 |
| 562.95 TB | 163.87 TB | 37 |
| 1.13 PB | 328.11 TB | 38 |
| 2.25 PB | 656.76 TB | 39 |
| 4.50 PB | 1.31 PB | 40 |
| 9.01 PB | 2.63 PB | 41 |