Kademlia
Kademlia is a distributed hash table (DHT) algorithm used in peer-to-peer networks to efficiently store and retrieve data without relying on centralized servers. It organizes nodes into an overlay network that ensures efficient routing using a binary tree structure.
Kademlia Key Concepts
XOR Distance Metric
Kademlia uses a distance metric based on the XOR (exclusive OR) between any addresses. This allows nodes to calculate "distance" from each other. Lookups are made by recursively querying nodes that are progressively closer to the target.
Routing Table
Each node in a Kademlia network maintains a routing table containing information about other nodes, organized by the XOR distance between node IDs.
Kademlia Advantages
Efficient Lookups
To retrieve a specific chunk, a node uses Kademlia's lookup process to find and fetch the chunk from a node in the neighborhood where it is stored. The number of hops required for a chunk to be retrieved is logarithmic to the number of nodes in the network, meaning lookups remain efficient even as the network grows larger and larger.
Fault Tolerance
Because nodes' peer lists are regularly refreshed through lookups and interactions, and because redundant copies of data are replicated within the network, the network remains functional even when individual nodes leave or fail.
Scalability
Kademlia's design allows it to scale to large networks, as each node only needs to keep track of a small subset of the total nodes in the network. The required set of connected peers grows logarithmically with the number of nodes, making it efficient even in large networks.
Kademlia in Swarm
As mentioned above, Swarm's version of Kademlia differs from commonly used implementations of Kademlia in several important ways:
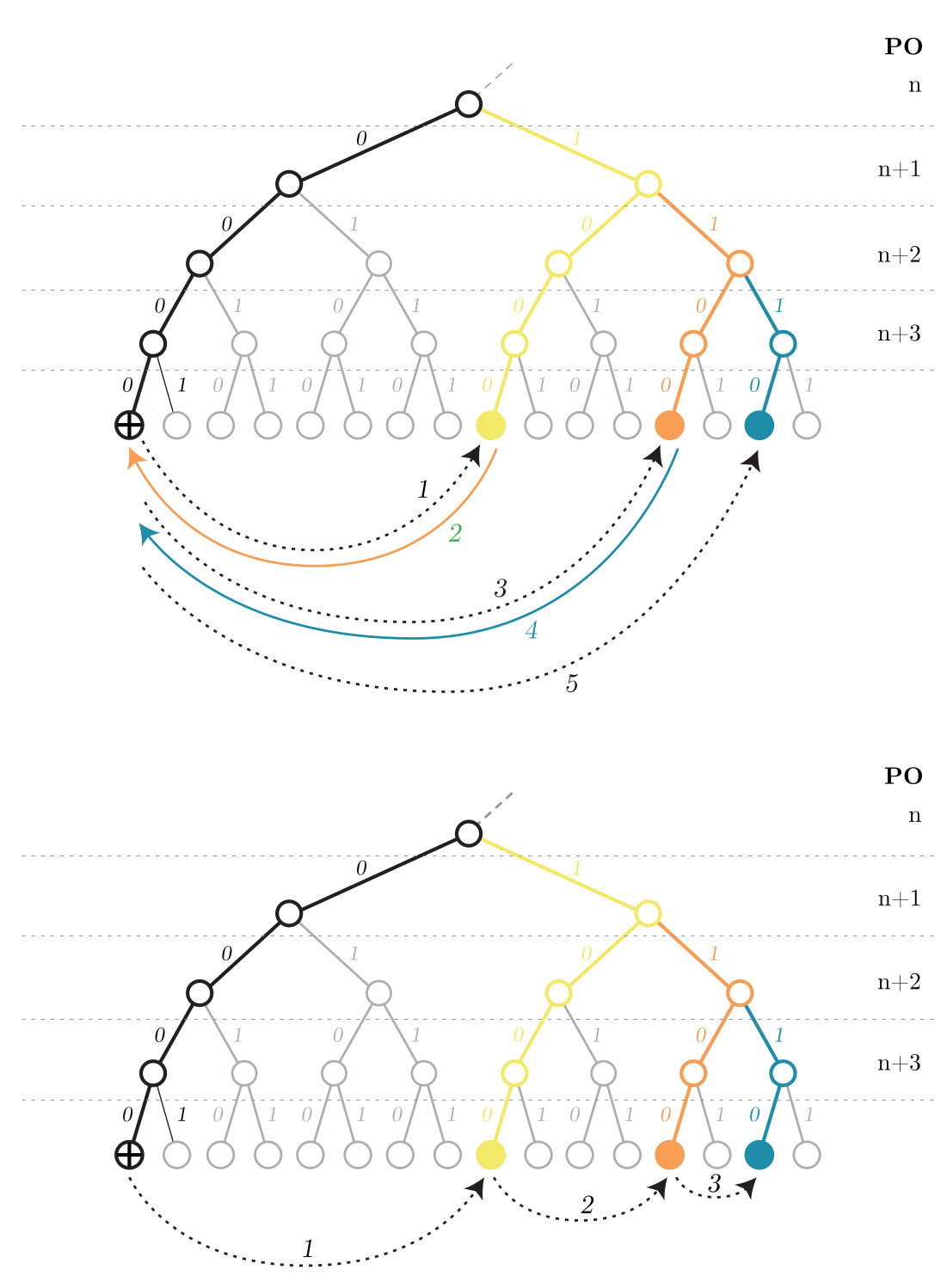
Proximity Order & Neighborhoods
Swarm introduces the concept of proximity order (PO) as a discrete measure of node relatedness between two addresses. In contrast with Kademlia distance which is an exact measure of relatedness, PO is used to measure the relatedness between two addresses on a discrete scale based on the number of shared leading bits. Since this metric ignores all the bits after the shared leading bits, it is not an exact measure of distance between any two addresses.
In Swarm's version of Kademlia, nodes are grouped into neighborhoods of nodes based on PO (ie., neighborhood are composed of nodes which all share the same leading binary prefix bits). Each neighborhood of nodes is responsible for storing the same set of chunks.
Neighborhoods are important for ensuring data redundancy, and they also play a role in the incentives system which guarantees nodes are rewarded for contributing resources to the network.
Forwarding Kademlia
Kademlia comes in two flavors, iterative and forwarding. In iterative Kademlia, the requesting node directly queries each node it contacts for nodes that are progressively closer to the target until the node with the requested chunk is found. The chunk is then sent directly from the storer node to the node which initiated the request.
In contrast, Swarm makes use of forwarding Kademlia. Here each node forwards the query to the next closest node in the network, and this process continues until a node with the requested chunk is found. Once the chunk is found, it is sent back along the same chain of nodes rather than sent directly to the initiator of the request.
The main advantage of forwarding Kademlia is that it maintains the anonymity of the node which initiated the request.
Neighborhood Based Storage Incentives
Swarm introduces a storage incentives layer on top of its Kademlia implementation in order to reward nodes for continuing to provide resources to the network. Neighborhoods play a key role in the storage incentives mechanism. Storage incentives take the role of a "game" in which nodes play to win a reward for storing the correct data. Each round in the game, one neighborhood is chosen to play, and all nodes within the same neighborhood participate as a group. The nodes each compare the data they are storing with each other to make sure they are all storing the data they are responsible for, and one node is chosen to win from among the group. You can read more about how storage incentives work in the dedicated page for storage incentives.