Staking
Quickstart Guide
This guide will walk you through staking xBZZ and participating in the redistribution game to earn storage incentives.
Staking requires a fully synced full node and a minimum of 10 xBZZ. See detailed staking requirements below.
Prerequisites
- A small amount of xDAI to pay transaction fees - ~0.01 xDAI is enough to start
- At least 10 xBZZ to deposit as non-refundable stake
- A fully synced full Bee node
If you don't already have xDAI or xBZZ, you will need to get some.
Step 1: Fund Your Node with xDAI and xBZZ
Your node needs xDAI to pay for transaction fees on Gnosis Chain, and also needs xBZZ to deposit as stake.
First, find your node's address using:
swarm-cli addresses
This will print your node's various addresses. The one you need to fund is Ethereum
The Ethereum term here refers to an Ethereum style address on Gnosis Chain. Do not send funds to the address on the Ethereum chain itself.
Node Addresses
------------------------------------------------------------------------------------------------------------------
Ethereum: 9a73f283cd9211b96b5ec63f7a81a0ddc847cd93
...
Then, use the following command to check how much is required:
swarm-cli status
At the bottom of the results printed to the terminal you will find the Redistribution section. From there you will see the Minimum gas funds item. That value is the minimum amount required to participate in a single redistribution round.
If you plan on operating your node for an extended period, you will want to deposit quite a bit more than the minimum. You can start with 0.01 xDAI to cover fees for the next few weeks/months of active staking, and then monitor actual usage and top-up when needed.
Redistribution
Reward: 0.0000000000000000
Has sufficient funds: true
Fully synced: true
Frozen: false
Last selected round: 263526
Last played round: 0
Last won round: 0
Minimum gas funds: 0.000000000326250000
Finally, send the required xDAI and xBZZ to the address you got from swarm-cli addresses.
You will need to send at least 10 xBZZ to get started staking.
Send 20 xBZZ if using the reserve doubling feature.
Step 2: Stake xBZZ
Once your node has xDAI, stake at least 10 xBZZ (this is non-refundable).
You can use the following swarm-cli command to stake 10 xBZZ:
swarm-cli stake deposit --bzz 10
After a moment, the staking transaction will complete. Then you can check that the transaction was successful:
swarm-cli stake status
Staked xBZZ: 10
Optional: Stake 20 xBZZ if using the reserve doubling feature.
Step 3: Check Status
After staking you should check your node's status to make sure it is fully synced, fully funded, and operating properly.
Step 4: Monitor & Maximize Rewards
✅ Make sure you are using a stable Gnosis Chain RPC endpoint.
✅ Check your node's status to ensure it's operating properly.
✅ Check /rchash to ensure your node's performance is sufficient.
Staking Overview
To earn storage incentives by participating in the redistribution game, full nodes must first deposit a minimum of 10 xBZZ as non-refundable stake. xDAI is also required to pay for ongoing Gnosis Chain transactions related to the redistribution game.
Only stake your xBZZ if you intend to participate as a full node, as withdrawals are not possible.
Requirements
- A full node - see full node recommend specs.
- A high-performance RPC endpoint connection to Gnosis Chain.
- A minimum of 10 xBZZ to be used as non-refundable stake (the requirement is increased if reserve doubling is used).
Check Status
Use the /redistributionstate endpoint of the API to get more information about the redistribution status of the node.
curl -X GET http://localhost:1633/redistributionstate | jq
{
"minimumFunds": "18750000000000000",
"hasSufficientFunds": true,
"isFrozen": false,
"isFullySynced": true,
"phase": "commit",
"round": 176319,
"lastWonRound": 176024,
"lastPlayedRound": 176182,
"lastFrozenRound": 0,
"block": 26800488,
"reward": "10479124611072000",
"fees": "30166618102500000"
}
"minimumFunds": <integer>- The minimum xDAI needed to play a single round of the redistribution game (the unit is 1e-18 xDAI)."hasSufficientFunds": <bool>- Shows whether the node has enough xDAI balance to submit at least five storage incentives redistribution related transactions. Iffalsethe node will not be permitted to participate in next round."isFrozen": <bool>- Shows node frozen status."isFullySynced": <bool>- Shows whether node's localstore has completed full historical syncing with all connected peers."phase": <string>- Current phase of redistribution game (commit,reveal, orclaim)."round": <integer>- Current round of redistribution game. The round number is determined by dividing the current Gnosis Chain block height by the number of blocks in one round. One round takes 152 blocks, so using the "block" output from the example above we can confirm that the round number is 176319 (block 26800488 / 152 blocks = round 176319)."lastWonRound": <integer>- Number of round last won by this node."lastPlayedRound": <integer>- Number of the last round where node's neighborhood was selected to participate in redistribution game."lastFrozenRound": <integer>The number the round when node was last frozen."block": <integer>- Gnosis block of the current redistribution game."reward": <string (BigInt)>- Record of total reward received in PLUR."fees": <string (BigInt)>- Record of total spent in 1E-18 xDAI on all redistribution related transactions.
Do not shut down or update your node during an active redistribution round as it may cause them to lose out on winnings or become frozen. To see if your node is playing the current round, check if lastPlayedRound equals round in the output from the /redistributionstate endpoint.
You should also check the /status endpoint:
curl -s http://localhost:1633/status | jq
{
"peer": "da7e5cc3ed9a46b6e7491d3bf738535d98112641380cbed2e9ddfe4cf4fc01c4",
"proximity": 0,
"beeMode": "full",
"reserveSize": 3747532,
"pullsyncRate": 0,
"storageRadius": 10,
"connectedPeers": 183,
"neighborhoodSize": 12,
"batchCommitment": 133828050944,
"isReachable": true
}
Expected values for a healthy staking node:
"beeMode": full"pullsyncRate": 0"isReachable": true
If your node is not operating properly such as getting frozen or not participating in any rounds, see the troubleshooting section.
Partial Stake Withdrawals
If the price of xBZZ rises significantly and provides excess collateral, a partial withdrawal will be allowed down to the minimum required stake:
Check for withdrawable stake
curl http://localhost:1633/stake/withdrawable | jq
If there is any stake available for withdrawal, the amount will be displayed in PLUR:
{
"withdrawableStake": "18411"
}
Withdraw available stake
If there is any stake available for withdrawal, you can withdraw it using the DELETE method on /stake/withdrawable:
curl -X DELETE http://localhost:1633/stake/withdrawable
Reserve Doubling
The reserve doubling feature enables nodes to store chunks from a neighboring "sister" area, effectively increasing their reserve capacity twofold. By maintaining chunks from this sister neighborhood, a node becomes eligible to join the redistribution game whenever the sister neighborhood is chosen, effectively doubling its chances of participating.
Although reserve doubling demands twice the disk storage and increases bandwidth usage for chunk syncing (with no additional bandwidth needed for chunk forwarding), its effect on CPU and RAM consumption remains minimal. This feature provides node operators with greater flexibility to optimize their nodes, aiming to achieve a higher reward-to-resource usage ratio.
Step by Step Guide
In order to double a node's reserve which has previously been operating without doubling, the reserve-capacity-doubling option must be updated from the default of 0 to 1 and restarted. There is also an increase in the xBZZ stake requirement from the minimum of 10 xBZZ to 20 xBZZ.
Step 1: Set reserve-capacity-doubling to 1.
The reserve doubling feature can be enabled by setting the new reserve-capacity-doubling config option to 1 using the configuration method of your choice.
Step 2: Stake at least 20 xBZZ
For doubling the reserve of a node which was previously operating which already has 10 xBZZ staked, simply stake an additional 10 xBZZ for a total of 20 xBZZ stake:
As always, ensure you properly convert the stake parameter to PLUR, where 1 PLUR equals 1e-16 xBZZ.
curl -X POST localhost:1633/stake/100000000000000000
Or for a new node with zero staked xBZZ, the entire 20 xBZZ can be staked at once:
curl -X POST localhost:1633/stake/200000000000000000
We can use the GET /stake endpoint to confirm the total stake for our node:
curl -s http://localhost:1633/stake | jq
{
"stakedAmount": "200000000000000000"
}
Step 3: Restart node
After ensuring the node has at least 20 xBZZ staked and the reserve-capacity-doubling option has been set to 1, restart the node.
After restarting your node, it should then begin syncing chunks from its sister neighborhood.
The /status/neighborhoods endpoint can be used to confirm that the node has doubled its reserve and is now syncing with its sister neighborhood:
{
"neighborhoods": [
{
"neighborhood": "01111101011",
"reserveSizeWithinRadius": 1148351,
"proximity": 10
},
{
"neighborhood": "01111101010",
"reserveSizeWithinRadius": 1147423,
"proximity": 11
}
]
}
The output should list both your original and sister neighborhood.
We can also check the /status endpoint to confirm our node is syncing new chunks:
curl -s http://localhost:1633/status | jq
{
"overlay": "be177e61b13b1caa20690311a909bd674a3c1ef5f00d60414f261856a8ad5c30",
"proximity": 256,
"beeMode": "full",
"reserveSize": 4192792,
"reserveSizeWithinRadius": 2295023,
"pullsyncRate": 1.3033333333333332,
"storageRadius": 10,
"connectedPeers": 18,
"neighborhoodSize": 1,
"batchCommitment": 388104192,
"isReachable": true,
"lastSyncedBlock": 6982430
}
We can see that the pullsyncRate value is above zero, meaning that our node is currently syncing chunks, as expected.
Maximize rewards
There are two main factors which determine the chances for a staking node to win a reward — neighborhood selection and stake density. Both of these should be considered together before starting up a Bee node for the first time. See the incentives page for more context.
Neighborhood selection
By default when running a Bee node for the first time the node will use the neighborhood suggestion tool from Swarmscan to find an optimal neighborhood. While it is possible to manually choose a neighborhood using the target-neighborhood config option, we recommend not to do so as the suggestion tool will pick neighborhoods in order to maximize node earnings and network health. Learn more.
Stake density
Stake density is defined as:
To learn more about stake density and the mechanics of the incentives system, see the incentives page.
Stake density determines the weighted chances of nodes within a neighborhood of winning rewards. The chance of winning within a neighborhood corresponds to stake density. Stake density can be increased by depositing more xBZZ as stake (note that stake withdrawals are not currently possible, so any staked xBZZ is not currently recoverable).
Generally speaking, the minimum required stake of 10 xBZZ is sufficient, and rewards can be better maximized by operating more nodes over a greater range of neighborhoods rather than increasing stake. However this may not be true for all node operators depending on how many different neighborhoods they operate nodes in, and it also may change as network dynamics continue to evolve (join the #node-operators Discord channel to stay up to date with the latest discussions about staking and network dynamics).
Chequebook verification
Full node operators can optionally enable chequebook verification to reject incoming peers whose chequebook balance falls below a configurable threshold. This can help filter out poorly funded peers from your node's connections.
Chequebook verification is disabled by default and can be enabled with the --chequebook-verification flag. The default minimum balance threshold is 11 BZZ and can be adjusted with --chequebook-min-balance. See the configuration page for details.
Neighborhood Hopping
There is a 2 round delay (with 152 Gnosis Chain blocks per redistribution game round) every time a node's neighborhood or stake is changed before it can participate in the redistribution game, moreover a node must fully sync the chunks from its new neighborhood before it can participate in the redistribution game, so hopping too frequently is not advised.
You can use the config option target-neighborhood to switch your node over to a new neighborhood. You may wish to use this option if your node's neighborhood becomes overpopulated.
Checking neighborhood population
For a quick check of your node's neighborhood population, we can use the /status endpoint:
curl -s http://localhost:1633/status | jq
{
"peer": "e7b5c1aac67693268fdec98d097a8ccee1aabcf58e26c4512ea888256d0e6dff",
"proximity": 0,
"beeMode": "full",
"reserveSize": 1055543,
"reserveSizeWithinRadius": 1039749,
"pullsyncRate": 42.67013868148148,
"storageRadius": 11,
"connectedPeers": 140,
"neighborhoodSize": 6,
"batchCommitment": 74463051776,
"isReachable": false
}
Here we can see that at the current storageRadius of 11, our node is in a neighborhood with size 6 from the neighborhoodSize value.
Using the Swarmscan neighborhoods tool we can see there are many neighborhoods with fewer nodes, so it would benefit us to move to less populated neighborhood:
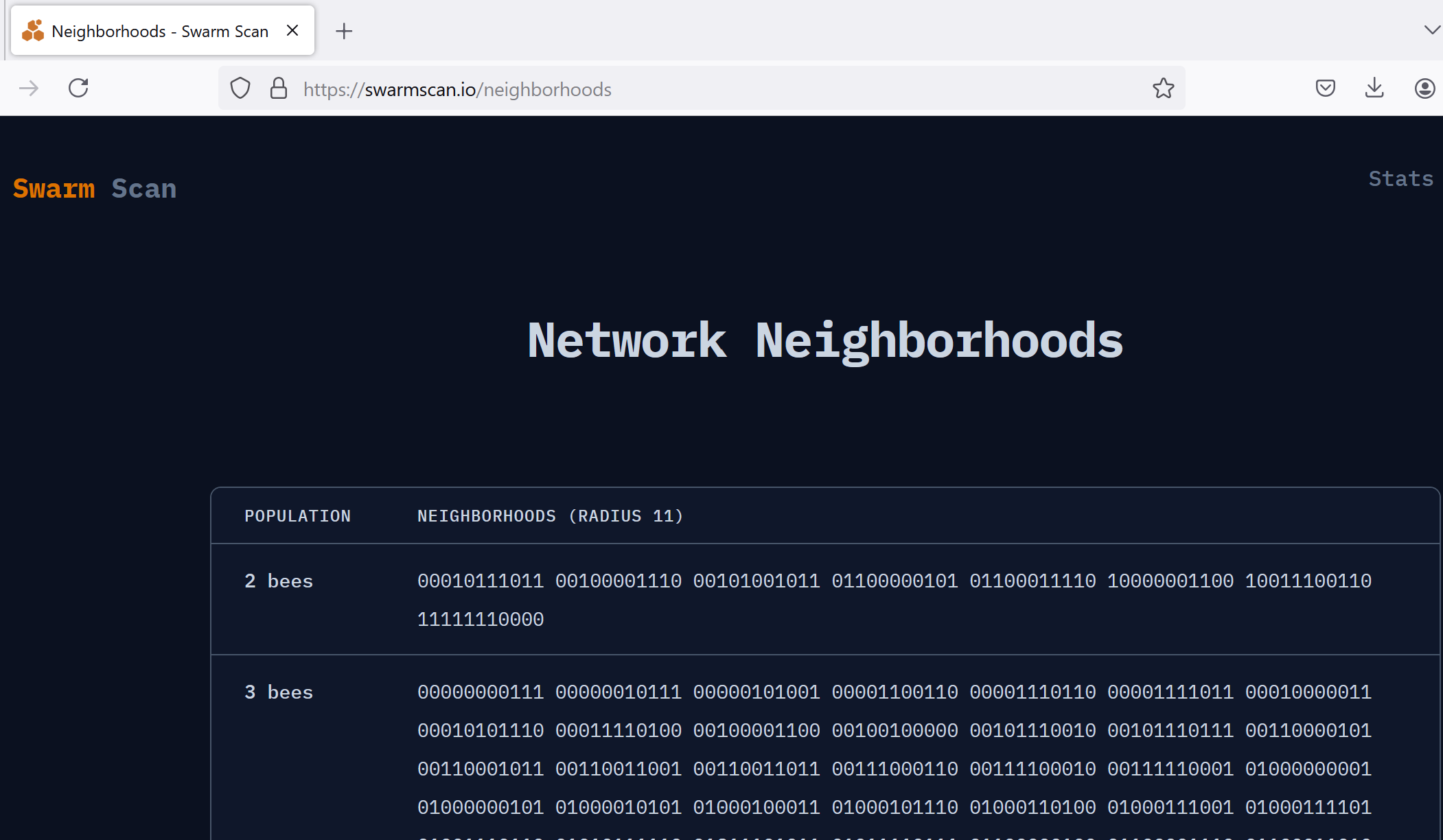
While you might be tempted to simply pick one of these less populated neighborhoods, it is best practice to use the neighborhood suggester API instead, since it will help to prevent too many node operators rapidly moving to the same underpopulated neighborhoods, and also since the suggester takes a look at the next depth down to make sure that even in case of a neighborhood split, your node will end up in the smaller neighborhood.
curl -s https://api.swarmscan.io/v1/network/neighborhoods/suggestion
Copy the binary number returned from the API:
{"neighborhood":"01100011110"}
Use the binary number you just copied and set it as a string value for the target-neighborhood option in your config.
## bee.yaml
target-neighborhood: "01100011110"
Stake Migration
If a new Bee release includes an updated staking contract, then you will be required to migrate your node's stake in order to continue normal operation. The stake migration process consists of the following steps:
- Withdraw xBZZ
- Stop node
- Update and restart
- Re-stake to the new contract
Step 1: Withdraw xBZZ
When a new version of Bee is released with an updated staking contract, the previous staking contract will be disabled, and stake withdrawals will be enabled.
Once the contract is disabled, stake can be withdrawn by calling the /stake endpoint with the DELETE method:
curl -X DELETE http://localhost:1633/stake
This command will withdraw all stake from the node to the node’s Gnosis Chain address.
Confirm that the stake was withdrawn:
curl -s http://localhost:1633/stake | jq
The value for stakedAmount should now be zero:
{
"stakedAmount": "0"
}
Step 2: Stop node
This step will vary depending on how the node was set up:
sudo systemctl stop bee
or
docker compose down
or
docker stop <container_name_or_id>
etc.
Step 3: Update and restart
Before every Bee client upgrade, it is best practice to ALWAYS take a full backup of your node.
After withdrawing stake and stopping the node, update to the newest version of Bee. After updating, restart the node.
You can use the /health endpoint to confirm your current Bee version:
curl -s http://localhost:1633/health | jq
To confirm a successful update, check that the value for the "version" field in the results corresponds to the version number of the latest Bee release.
For example, if the latest version was 2.8.1, it would look like this:
{
"status": "ok",
"version": "2.8.1-7cf53193",
"apiVersion": "8.1.0"
}
Make sure to check the latest version number yourself, as the versions shown in examples in this guide may not always be up to date with the latest.
Step 4: Re-stake xBZZ
After upgrading to the latest version and restarting, xBZZ should be re-staked into the new staking contract so that the node can continue to participate in the redistribution game.
To stake the minimum required 10 xBZZ:
Make sure to modify to the correct staking amount in case your node is using reserve doubling.
curl -X POST localhost:1633/stake/100000000000000000
Confirm that the staking transaction was successful:
curl -s http://localhost:1633/stake | jq
The expected output after staking the minimum of 10 xBZZ:
{
"stakedAmount": "100000000000000000"
}
Congratulations! You have performed a successful stake migration and your node will now continue to operate as normal.
Troubleshooting
In this section we cover several commonly seen issues encountered for staking nodes participating in the redistribution game. If you don't see your issue covered here or require additional guidance, check out the #node-operators Discord channel where you will find support from other node operators and community members.
Frozen node
A node will be frozen when the reserve commitment hash it submits in its commit transaction does not match the correct hash. The reserve commitment hash is used as proof that a node is storing the chunks it is responsible for. It will not be able to play in the redistribution game during the freezing period. See the penalties section for more information.
Check frozen status
You can check your node's frozen status using the /redistributionstate endpoint:
curl -X GET http://localhost:1633/redistributionstate | jq
{
"minimumFunds": "18750000000000000",
"hasSufficientFunds": true,
"isFrozen": false,
"isFullySynced": true,
"phase": "commit",
"round": 176319,
"lastWonRound": 176024,
"lastPlayedRound": 176182,
"lastFrozenRound": 0,
"block": 26800488,
"reward": "10479124611072000",
"fees": "30166618102500000"
}
The relevant fields here are isFrozen and lastFrozenRound, which respectively indicate whether the node is currently frozen and the last round in which the node was frozen.
Diagnosing freezing issues
In order to diagnose the cause of freezing issues we must compare our own node's status to that of other nodes within the same neighborhood by comparing the results from our own node returned from the /status endpoint to the other nodes in the same neighborhood which can be found from the /status/peers endpoint.
First we check our own node's status:
curl -s localhost:1633/status | jq
{
"peer": "da7e5cc3ed9a46b6e7491d3bf738535d98112641380cbed2e9ddfe4cf4fc01c4",
"proximity": 0,
"beeMode": "full",
"reserveSize": 3747532,
"pullsyncRate": 0,
"storageRadius": 10,
"connectedPeers": 183,
"neighborhoodSize": 12,
"batchCommitment": 133828050944,
"isReachable": true
}
And next we will find the status for all the other nodes in the same neighborhood as our own.
curl -s localhost:1633/status/peers | jq
The /status/peers endpoint returns all the peers of our node, but we are only concerned with peers in the same neighborhood as our own node. Nodes whose proximity value is equal to or greater than our own node's storageRadius value all fall into the same neighborhood as our node, so the rest have been omitted in the example output below:
{
...
{
"peer": "da33f7a504a74094242d3e542475b49847d1d0f375e0c86bac1c9d7f0937acc0",
"proximity": 9,
"beeMode": "full",
"reserveSize": 3782924,
"pullsyncRate": 0,
"storageRadius": 10,
"connectedPeers": 188,
"neighborhoodSize": 11,
"batchCommitment": 133828050944,
"isReachable": true
},
{
"peer": "da4b529cc1aedc62e31849cf7f8ab8c1866d9d86038b857d6cf2f590604387fe",
"proximity": 10,
"beeMode": "full",
"reserveSize": 3719593,
"pullsyncRate": 0,
"storageRadius": 10,
"connectedPeers": 176,
"neighborhoodSize": 11,
"batchCommitment": 133828050944,
"isReachable": true
},
{
"peer": "da5d39a5508fadf66c8665d5e51617f0e9e5fd501e429c38471b861f104c1504",
"proximity": 10,
"beeMode": "full",
"reserveSize": 3777241,
"pullsyncRate": 0,
"storageRadius": 10,
"connectedPeers": 198,
"neighborhoodSize": 12,
"batchCommitment": 133828050944,
"isReachable": true
},
{
"peer": "da4cb0d125bba638def55c0061b00d7c01ed4033fa193d6e53a67183c5488d73",
"proximity": 10,
"beeMode": "full",
"reserveSize": 3849125,
"pullsyncRate": 0,
"storageRadius": 10,
"connectedPeers": 181,
"neighborhoodSize": 13,
"batchCommitment": 133828050944,
"isReachable": true
},
{
"peer": "da4b1cd5d15e061fdd474003b5602ab1cff939b4b9e30d60f8ff693141ede810",
"proximity": 10,
"beeMode": "full",
"reserveSize": 3778452,
"pullsyncRate": 0,
"storageRadius": 10,
"connectedPeers": 183,
"neighborhoodSize": 12,
"batchCommitment": 133827002368,
"isReachable": true
},
{
"peer": "da49e6c6174e3410edad2e0f05d704bbc33e9996bc0ead310d55372677316593",
"proximity": 10,
"beeMode": "full",
"reserveSize": 3779560,
"pullsyncRate": 0,
"storageRadius": 10,
"connectedPeers": 185,
"neighborhoodSize": 12,
"batchCommitment": 133828050944,
"isReachable": true
},
{
"peer": "da4cdab480f323d5791d3ab8d22d99147f110841e44a8991a169f0ab1f47d8e5",
"proximity": 10,
"beeMode": "full",
"reserveSize": 3778518,
"pullsyncRate": 0,
"storageRadius": 10,
"connectedPeers": 189,
"neighborhoodSize": 11,
"batchCommitment": 133828050944,
"isReachable": true
},
{
"peer": "da4ccec79bc34b502c802415b0008c4cee161faf3cee0f572bb019b117c89b2f",
"proximity": 10,
"beeMode": "full",
"reserveSize": 3779003,
"pullsyncRate": 0,
"storageRadius": 10,
"connectedPeers": 179,
"neighborhoodSize": 10,
"batchCommitment": 133828050944,
"isReachable": true
},
{
"peer": "da69d412b79358f84b7928d2f6b7ccdaf165a21313608e16edd317a5355ba250",
"proximity": 11,
"beeMode": "full",
"reserveSize": 3712586,
"pullsyncRate": 0,
"storageRadius": 10,
"connectedPeers": 189,
"neighborhoodSize": 12,
"batchCommitment": 133827002368,
"isReachable": true
},
{
"peer": "da61967b1bd614a69e5e83f73cc98a63a70ebe20454ca9aafea6b57493e00a34",
"proximity": 11,
"beeMode": "full",
"reserveSize": 3780190,
"pullsyncRate": 0,
"storageRadius": 10,
"connectedPeers": 182,
"neighborhoodSize": 13,
"batchCommitment": 133828050944,
"isReachable": true
},
{
"peer": "da7b6a268637cfd6799a9923129347fc3d564496ea79aea119e89c09c5d9efed",
"proximity": 13,
"beeMode": "full",
"reserveSize": 3721494,
"pullsyncRate": 0,
"storageRadius": 10,
"connectedPeers": 188,
"neighborhoodSize": 14,
"batchCommitment": 133828050944,
"isReachable": true
},
{
"peer": "da7a974149543df1b459831286b42b302f22393a20e9b3dd9a7bb5a7aa5af263",
"proximity": 13,
"beeMode": "full",
"reserveSize": 3852986,
"pullsyncRate": 0,
"storageRadius": 10,
"connectedPeers": 186,
"neighborhoodSize": 12,
"batchCommitment": 133828050944,
"isReachable": true
}
]
}
Now that we have the status for our own node and all its neighborhood peers we can begin to diagnose the issue through a series of checks outlined below:
If you are able to identify and fix a problem with your node from the checklist below, it's possible that your node's reserve has become corrupted. Therefore, after fixing the problem, stop your node, and repair your node according to the instructions in the section following the checklist.
-
Compare
reserveSizewith peersThe
reserveSizevalue is the number of chunks stored by a node in its reserve. The value forreserveSizefor a healthy node should be around +/- 1% the size of most other nodes in the neighborhood. In our example, for our node'sreserveSizeof 3747532, it falls within that normal range. This does not guarantee our node has no missing or corrupted chunks, but it does indicate that it is generally storing the same chunks as its neighbors. If it falls outside this range, see the next section for instructions on repairing reserves. -
Compare
batchCommitmentwith peersThe
batchCommitmentvalue shows how many chunks would be stored if all postage batches were fully utilised. It also represents whether the node has fully synced postage batch data from on-chain. If your node'sbatchCommitmentvalue falls below that of its peers in the same neighborhood, it could indicate an issue with your blockchain RPC endpoint that is preventing it from properly syncing on-chain data. If you are running your own node, check your setup to make sure it is functioning properly, or check with your provider if you are using a 3rd party service for your RPC endpoint. -
Check
pullsyncRateThe
pullsyncRatevalue measures the speed at which a node is syncing chunks from its peers. Once a node is fully synced,pullsyncRateshould go to zero. IfpullsyncRateis above zero it indicates that your node is still syncing chunks, so you should wait until it goes to zero before doing any other checks. IfpullsyncRateis at zero but your node'sreserveSizedoes not match its peers, you should check whether your network connection and RPC endpoint are stable and functioning properly. A node should be fully synced after several hours at most. -
Check most recent
blocknumberThe
blockvalue returned from the/redistributionstateendpoint shows the most recent block a node has synced. If this number is far behind the actual more recent block then it indicates an issue with your RPC endpoint or network. If you are running your own node, check your setup to make sure it is functioning properly, or check with your provider if you are using a 3rd party service for your RPC endpoint.curl -X GET http://localhost:1633/redistributionstate | jq{"minimumFunds": "18750000000000000","hasSufficientFunds": true,"isFrozen": false,"isFullySynced": true,"phase": "commit","round": 176319,"lastWonRound": 176024,"lastPlayedRound": 176182,"lastFrozenRound": 0,"block": 26800488,"reward": "10479124611072000","fees": "30166618102500000"} -
Check peer connectivity
Compare the value of your node's
neighborhoodSizefrom the/statusendpoint and theneighborhoodSizeof its peers in the same neighborhood from the/status/peersendpoint. The figure should be generally the same (although it may fluctuate slightly up or down at any one point in time). If your node'sneighborhoodSizevalue is significantly different and remains so over time then your node likely has a connectivity problem. Make sure to check your network environment to ensure your node is able to communicate with the network.
If no problems are identified during these checks it likely indicates that your node was frozen in error and there are no additional steps you need to take.
Repairing corrupt reserve
If you have identified and fixed a problem causing your node to become frozen or have other reason to believe that your node's reserves are corrupted then you should repair your node's reserve using the db repair-reserve command.
First stop your node, and then run the following command:
Make sure to replace /home/bee/.bee with your node’s data directory if it differs from the one shown in the example. Make sure that the directory you specify is the root directory for your node’s data files, not the localstore directory itself. This is the same directory specified using the data-dir option in your node’s configuration.
bee db repair-reserve --data-dir=/home/bee/.bee
After the command has finished running, you may restart your node.
Node occupies unusually large space on disk
During normal operation of a Bee node, it should not take up more than ~30 GB of disk space. In the rare cases when the node's occupied disk space grows larger, you may need to use the compaction db compact command.
To prevent any data loss, operators should run the compaction on a copy of the localstore directory and, if successful, replace the original localstore with the compacted copy.
The command is available as a sub-command under db as such (make sure to replace the value for --data-dir with the correct path to your bee node's data folder if it differs from the path shown in the example):
bee db compact --data-dir=/home/bee/.bee
Node not participating in redistribution
First check that the node is fully synced, is not frozen, and has sufficient funds to participate in staking. To check node sync status, call the redistributionstate endpoint:
curl -X GET http://localhost:1633/redistributionstate | jq
Response:
{
"minimumFunds": "18750000000000000",
"hasSufficientFunds": true,
"isFrozen": false,
"isFullySynced": true,
"phase": "commit",
"round": 176319,
"lastWonRound": 176024,
"lastPlayedRound": 176182,
"lastFrozenRound": 0,
"block": 26800488,
"reward": "10479124611072000",
"fees": "30166618102500000"
}
Confirm that hasSufficientFunds is true, and isFullySynced is true before moving to the next step. If hasSufficientFunds is false, make sure to add at least the amount of xDAI shown in minimumFunds (unit of 1e-18 xDAI). If the node was recently installed and isFullySynced is false, wait for the node to fully sync before continuing. After confirming the node's status, continue to the next step.
Run sampler process to benchmark performance
One of the most common issues affecting staking is the sampler process failing. The sampler is a resource intensive process which is run by nodes which are selected to take part in redistribution. The process may fail or time out if the node's hardware specifications aren't high enough. To check a node's performance the /rchash endpoint of the API may be used. See the /rchash section of the Bee API page for usage details.
If you are still experiencing problems, you can find more help in the node-operators Discord channel (for your safety, do not accept advice from anyone sending a private message on Discord).